Azure Cosmos DB — Getting Started and Creating a NoSQL Database

Azure Cosmos DB is a fully managed NoSQL database, designed to provide high availability, high throughput and low latency. In this article, I explore the benefits offered by Azure Cosmos DB and demonstrate how to create a NoSQL database within the Cosmos DB environment.
Cosmos DB is offered as a Platform as a Service (PaaS) on Azure, provides very fast reads and writes operations (generally within 10 milliseconds or less), and has comprehensive service-level agreements on throughput, latency, consistency, and availability. It is designed to allow developers to easily create and manage globally distributed, responsive, and highly available database applications.
Some of Azure Cosmos DB features are:
- Global distribution: it allows you to distribute your data across the globe, ensuring low-latency access to data for your users no matter where they are located.
- Multi-data models support: it provides native support for multiple data models, such as documents, key-value, graph, and column-family data.
- Automatic and instant scalability: it automatically scales throughput and storage based on your application’s needs, so you don’t have to worry about capacity planning. It has the ability to scale from thousands to hundreds of millions of requests per second.
- High availability: it ensures high availability for your data with automatic and instant failover, as well as configurable consistency levels to support a variety of application scenarios.
- Secure: it offers multiple options for securing your data, including network isolation, VNETs, and encryption at rest.
APIs in Azure Cosmos DB
Azure Cosmos DB offers multiple database APIs such as:
- NoSQL API: default API that allows you to interact with the data in a SQL query language style — Well-suited for applications with a flexible schema, where data is stored as JSON documents.
- Table API: stores key-value data — Designed for applications with simple key-value access patterns, similar to Azure Table Storage.
- MongoDB API: for document databases built on MongoDB — Allows MongoDB developers to migrate their existing applications to Azure Cosmos DB without major code changes.
- Gremlin API: for graph databases — Suitable for applications with complex relationships and network structures, such as social networks or fraud detection.
- Cassandra API: for wide-column storage — Ideal for applications that require a highly scalable, distributed, and fault-tolerant wide-column storage system.
- PostgreSQL API: ideal for starting on a single-node database with rich indexing, geospatial capabilities, and JSONB support. The PostgreSQL in Cosmos DB is built on native PostgreSQL. This is a good choice If you need a managed open-source relational database with high performance and geo-replication.
All the APIs offer automatic scaling of storage and throughput, flexibility, and performance guarantees. (Microsoft Docs)
Creating a Cosmos DB Account
To create a Cosmos DB database, search for Cosmos DB in the Azure portal:

Then click on “Create”:

On the next page, you can select which type of Cosmos DB account you want. For this example, I selected the “Azure Cosmos DB for NoSQL”:
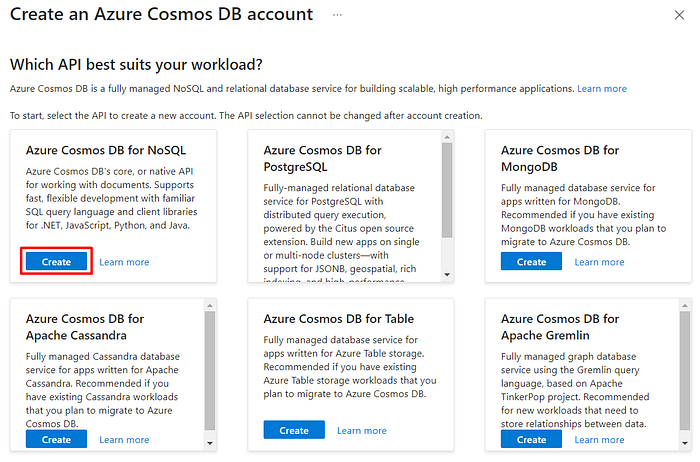
On the next page, fill in the necessary information. Be aware that for demonstration purposes I did not enable the “Availability Zones”, but this is something you might want to do in a production environment:
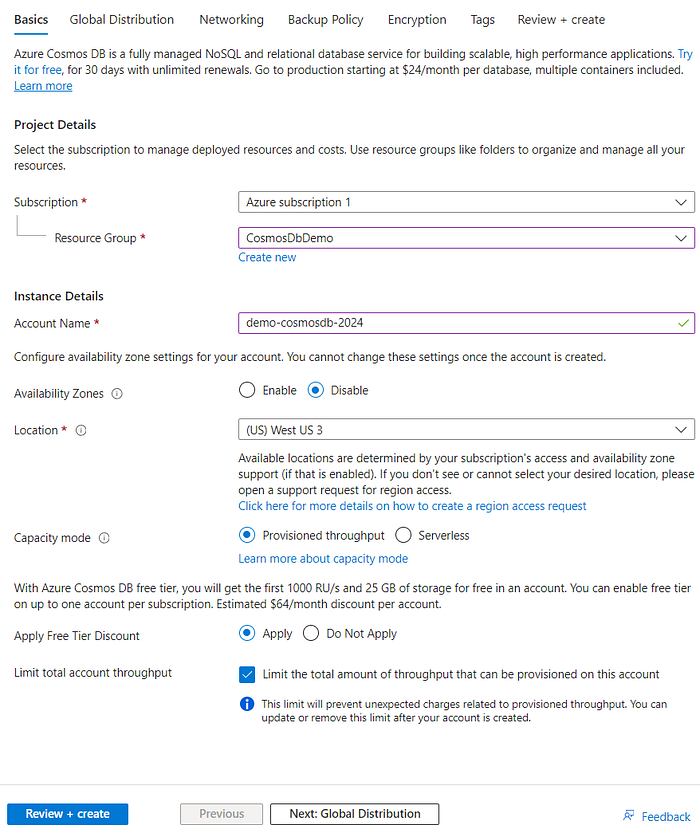
After clicking on “Review + create”, a validation will be run, and after that click in “Create” and your Cosmos DB account will be created:
Consistency levels in Azure Cosmos DB
Cosmos DB provides high availability for your data, and in order to achieve that, multiple copies of your data can be made. Cosmos DB internally handles the data replication between regions with consistency level guarantees of the level you’ve selected.
“Distributed databases that rely on replication for high availability, low latency, or both, must make a fundamental tradeoff between the read consistency, availability, latency, and throughput as defined by the PACELC theorem.” (Microsoft Docs)
For this reason, when you have more than one replica in different Azure regions, it’s important to select the consistency level that better fits your need. Cosmos DB offers the following consistency levels:
- Strong: This ensures that the reads are guaranteed to return the most recent committed version of an item. It ensures that all data is consistent, which means that will always return the latest (most updated) data. It has a higher latency (lower throughput).
- Bounded-Staleness: This allows that the data is not updated with the latest change for some period of time, but guarantees that will not be for more than “K” (a number of versions of the item), or that will not be more than “T” (a time interval), whichever is reached first. The reads can lag behind the writes by at most “K” version of an item or by “T” time interval (you can specify the maximum values for these metrics). This will always provide reads in write order. For a single region account, the minimum value of K and T is 10 write operations or 5 seconds, and for multi-region accounts the minimum value of K and T is 100.000 write operations or 300 seconds.
- Session: Within a single client session, the reads are guaranteed to honor the read-your-writes, and write-follows-reads guarantees. It guarantees that all read and write operations in a session will be consistent with each other. For example, the data will be the same for a session, and for other sessions, the data will be updated with some delay, but in the same order that was recorded. This approach assumes a single “writer” session or sharing the session token for multiple writes.
- Consistent Prefix: Guarantees that all read operations will return the most recent version of an item with a prefix of all prior writes. The updates will be seen after a gap, but the client will never see out of order writes.
- Eventual: Guarantees that the data will eventually be in a consistent stage after some time. For this level, there is no ordering guarantee for reads. It is the weaker consistency and has higher throughput. This is ideal in scenarios where the application does not require any ordering guarantees.
If you want to know more about Consistency Levels in Azure Cosmos DB, check Microsofts documentation by clicking here.
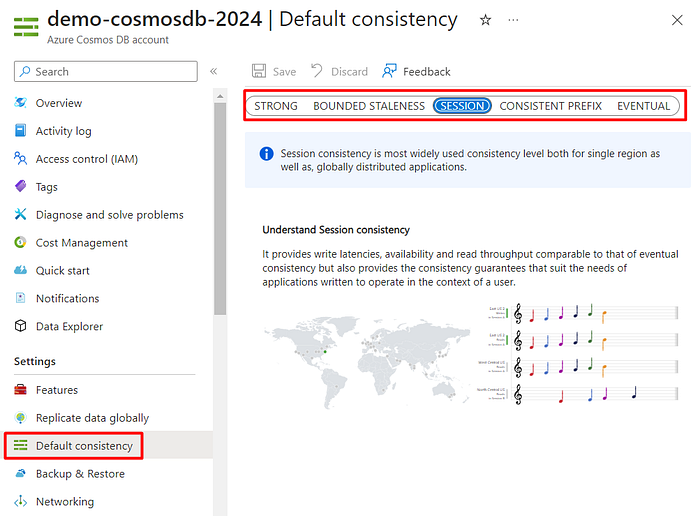
To configure the consistency level of your Cosmos DB account, you can go to the “Default consistency” page, and you can see/change the consistency level (don’t forget to save the change in case you change it):
Keys
On the Keys page, is where you can find the connection strings for your Database. You can see Read-write Keys and Read-only Keys:
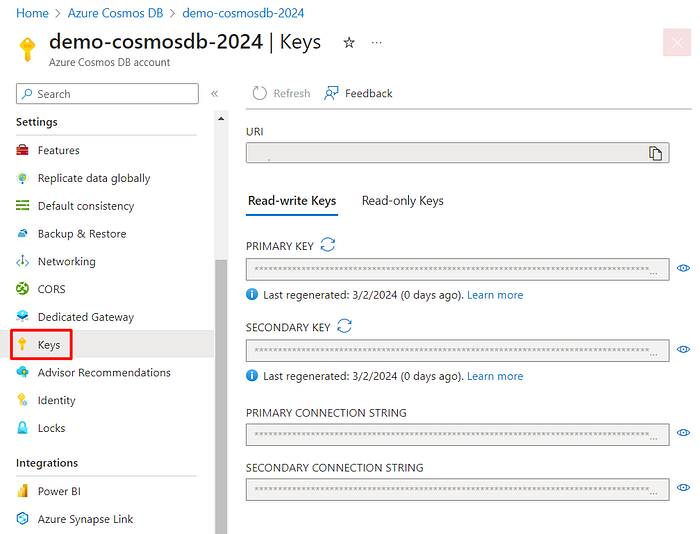
Note that there are two connection strings, and this is because in case you need to regenerate the primary key, you can use the secondary key in your apps, regenerate the primary one, and then add it to your apps, without interruption.
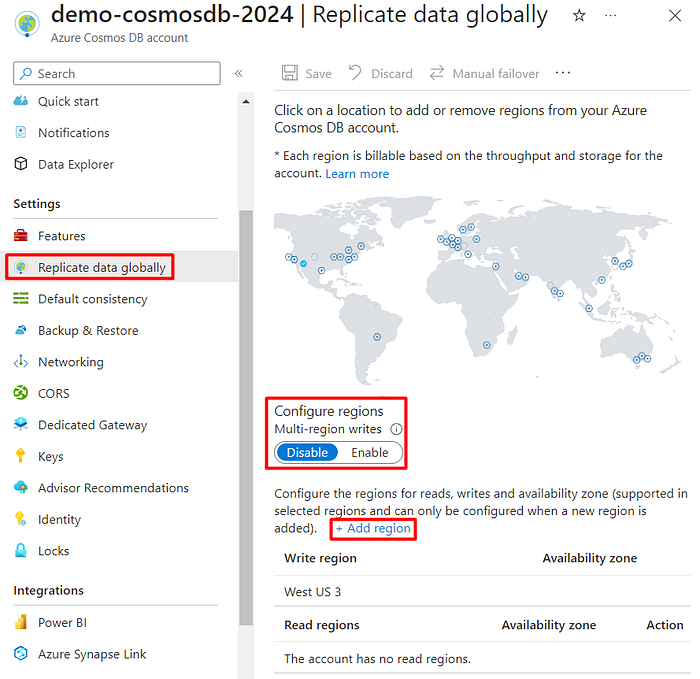
Replicate data globally
On this replication page, is where you can enable and configure geo-replication, which is a process that copies data across multiple Azure regions, providing both high availability and disaster recovery options for your Cosmos DB account. On this page, you can configure and add regions:
Creating a Cosmos DB Container
An Azure Cosmos DB container is where data is stored. When a container is created, you need to provide a partition key. This key is a property that you can define that will help Cosmos DB to distribute the data efficiently across partitions. You can set a partition key in the creation of the container — each item in Cosmos DB is associated with a partition key.
There are two types of partition keys:
- Logical Partition Key: They are formed based on the value of a partition key that is associated with each item in a container. All the items in a logical partition have the same partition key value. A logical partition consists of a set of items that have the same partition key. Entities that have the same partition key will live in the same logical partition server (a physical server might serve multiple logical partitions).
- Physical Partition Key: They are an internal implementation and entirely managed by Azure Cosmos DB.
A partition key should be a value that will not change. In case you need to change it, you will need to move the data to a new container with the new partition key.
Different from most relational databases, that scales up (vertical scaling), Cosmos DB scales out (horizontal scaling). The data is stored on one or more servers, called partitions — to increase throughput or storage, more partitions are added.
A container is horizontally partitioned across a set of machines within an Azure region and is distributed across all Azure regions associated with your Azure Cosmos DB account.
In the image below you can see a representation of the hierarchy of elements for a Cosmos DB account:

One Cosmos DB Account can contain multiple databases, and each database can have multiple containers.
Cosmos DB uses partitioning to scale individual containers in a database to meet the performance needs of your application. For demonstration purposes, I’m going to create a “Products” container, on which the partition key is the “category”.
After the creation of the Cosmos DB Account, go to the Cosmos DB account and in the Overview page click on “Add Container”:
On the next page, fill in the information for your database:
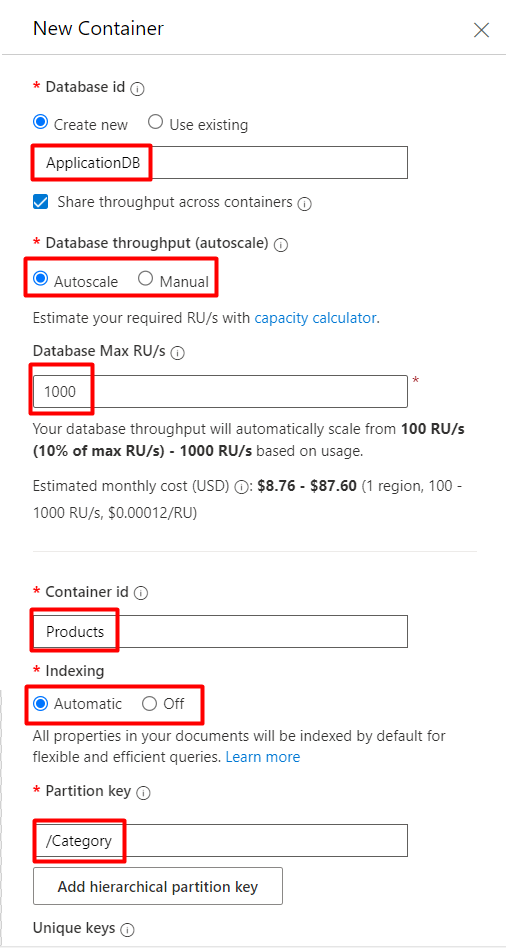
- Database id: This is the database name assigned to a Cosmos DB database.
- Database throughput: This determines the capacity for handling read and write operations on the database (container). You can set it to automatically scale or to manual scaling.
- Database Max RU/s: RU/s stands for Request Units per Second. Request Units (RUs) are a way to quantify the amount of resources consumed by database operations, including reads, writes, and queries. Request units are the currency for database operations in Cosmos DB. An RU is the cost of the combined system resources needed to read 1 KB item.
- Container id: This is the name assigned to a collection in a Cosmos DB database.
- Indexing: You can set on this property to Cosmos DB automatically indexes every property for all items in your container or you can choose to not create any indexes for the properties.
- Partition key: This is the partition key in a container, that is used to distribute and organize data across multiple logical partitions.
Then click on “Ok”. Now you can go to “Data Explorer”, and you can see the Database and the Container:

Below the container name, click on “Items”. As this was just created, it will be empty. You can click on “New Item” to add a new document to the container:
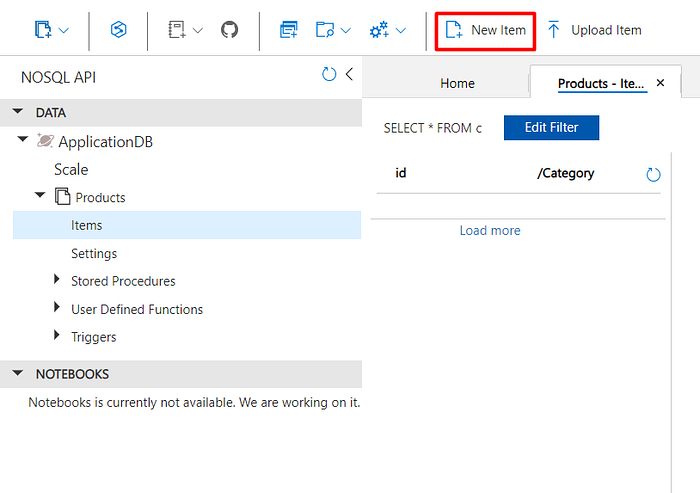
The data is stored in a document, which can be any structured data type, and generally, JSON (JavaScript Object Notation) is commonly used as the data format. The Azure Cosmos DB for NoSQL supports JSON natively. JSON is a lightweight data format and was built to be highly compatible with the literal notation of an object in the JavaScript language.
A default template with an id property will be created, you can add the properties you want. The id property is required and it is used to identify a document in a logical partition. If you don’t provide an id, a GUID value will be automatically added as the id. After adding the values you want, click on “Save”:
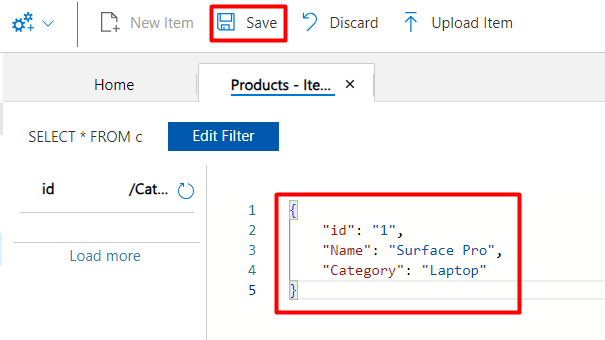
The document will be added to your database:
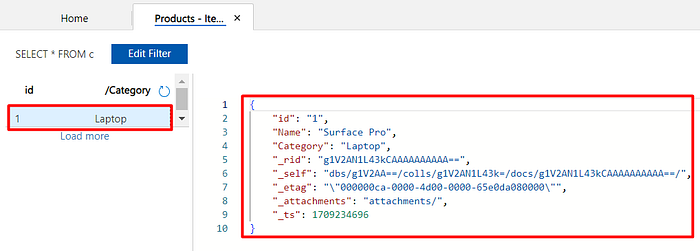
Note that a few properties were also automatically included in your document. Let me explain what are each of them:
- _rid: This stands for Resource ID. It is a unique identifier for the document in this container. This ID is system-generated and is used to uniquely identify and access the document.
- _self: This is a system-generated property that represents the self-link of the document, which is a unique URI that points directly to the document. It provides a way to address and retrieve the document.
- _etag: This is a unique identifier for the current version of the document. When a document is modified, the
_etagchanges. This is commonly used for optimistic concurrency control to prevent conflicting updates. - _attachments: This provides a link to the attachments associated with the document. In Cosmos DB, you can associate binary attachments (such as images or files) with documents. This property points to the location where attachments are stored.
- _ts: This is the timestamp of the last update of the document. This property is useful for tracking the temporal order of document modifications.
Querying data in Cosmos DB
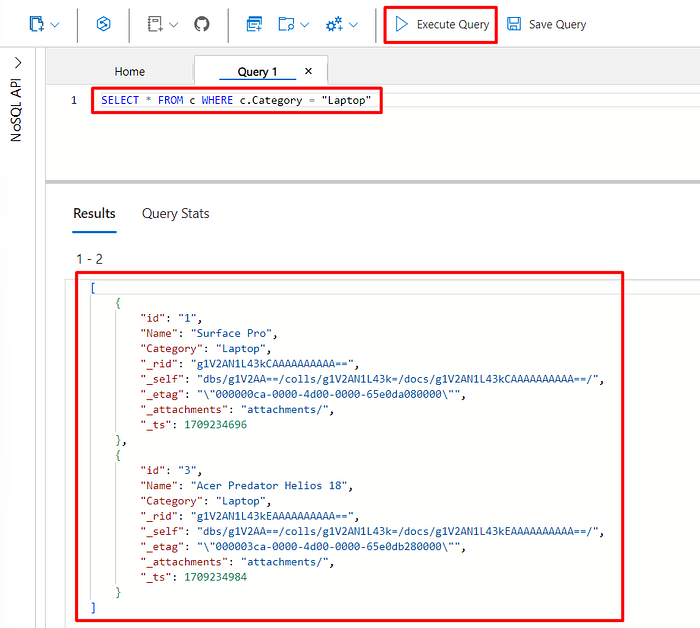
For demonstration purposes, I added a few more items in the container, in order to demonstrate how to query the data. For that, still in the Data Explorer page, click on “New SQL Query”:
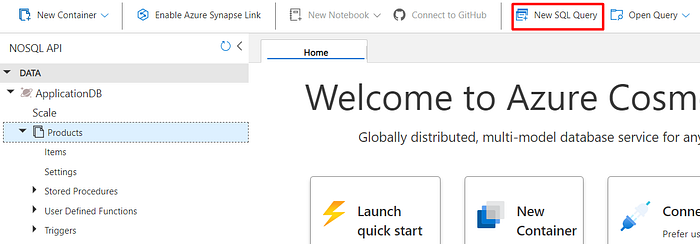
It will display a page where you can write and execute SQL queries. In the example below, I created a SELECT filtering by the category equal to “Laptop”, and you can see the result below:
Conclusion
Cosmos DB is a fully managed database service that can be used to build many kinds of applications such as Web apps, mobile, IoT and games. It can handle massive amounts of data, reads, and writes at a global scale with near-real response times. It can be a great choice when your app demands low latency and globally distributed data access.
